Apache OpenNLP¶
Apache OpenNLP is an open source library that provides solutions for some of the natural language processing tasks through its APIs and command line tools. Apache OpenNLP uses a machine learning approach for natural language processing tasks. It also provides some of the pre-built models for some of the tasks.
Apache OpenNLP supports the most common NLP tasks like tokenization, sentence segmentation, part of speech tagging, named entity extraction, chunking, parsing and coreference resolution. These tasks are usually required to build more advanced word processing services. OpenNLP also included maximum entropy and Perceptron-based machine learning.
Short description of the tasks:
Tokenization is the mechanism of splitting or fragmenting the sentences and words to its possible smallest morpheme called as token. Morpheme is smallest possible word after which it cannot be broken further. Tokenization could be sentence level and word level.
Sentence Segmentation is the process of dividing up a running text into sentences. One aspect which makes this task less straightforward than it sounds is the presence of punctuation marks that can be used either to indicate a full stop or to form abbreviations and the like.
Part of Speech-Tagging is a process of converting a sentence to forms – list of words, list of tuples (where each tuple is having a form (word, tag)). The tag is a part-of-speech tag, and signifies whether the word is a noun, adjective, verb, and so on.
Extraction of named entities means the automatic identification and classification of proper names. A proper name is a sequence of words that describes a real existing entity, such as a person, city, or company.
Chunking is the job of a chunker that breaks the sentence into groups( of words) containing sequential words of sentence, that belong to a noun group, verb group, etc.
Parsing is the process of determining the syntactic structure of a text by analyzing its constituent words based on an underlying grammar (of the language).
The NLP tasks are provided by Apache OpenNLP through pre-built models for selected languages.
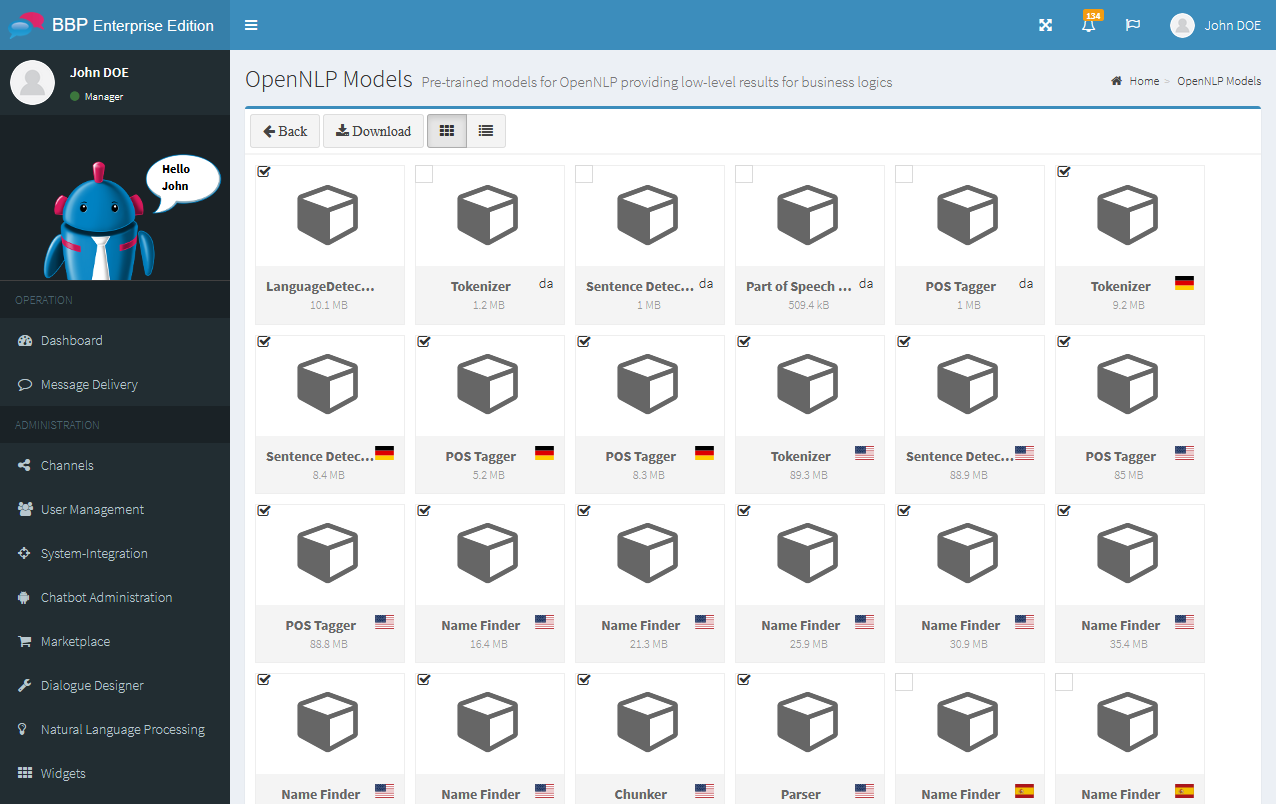
Add pre-trained OpenNLP model¶
The Business Bot platform allows you to download pre-built models so that they can be used by business logics. To add an OpenNLP model to the platform you need an Internet connection. Proceed as follows:
- In the navigation bar, click on
Natural Language Processing→NLP Models→Add Trained Models - Check the desired NLP model in the box on the top left and then click on
Download - The NLP model is now automatically downloaded and registered to the platform in the background. You can view the download status by clicking the flag icon for background tasks which is in the top navigation bar
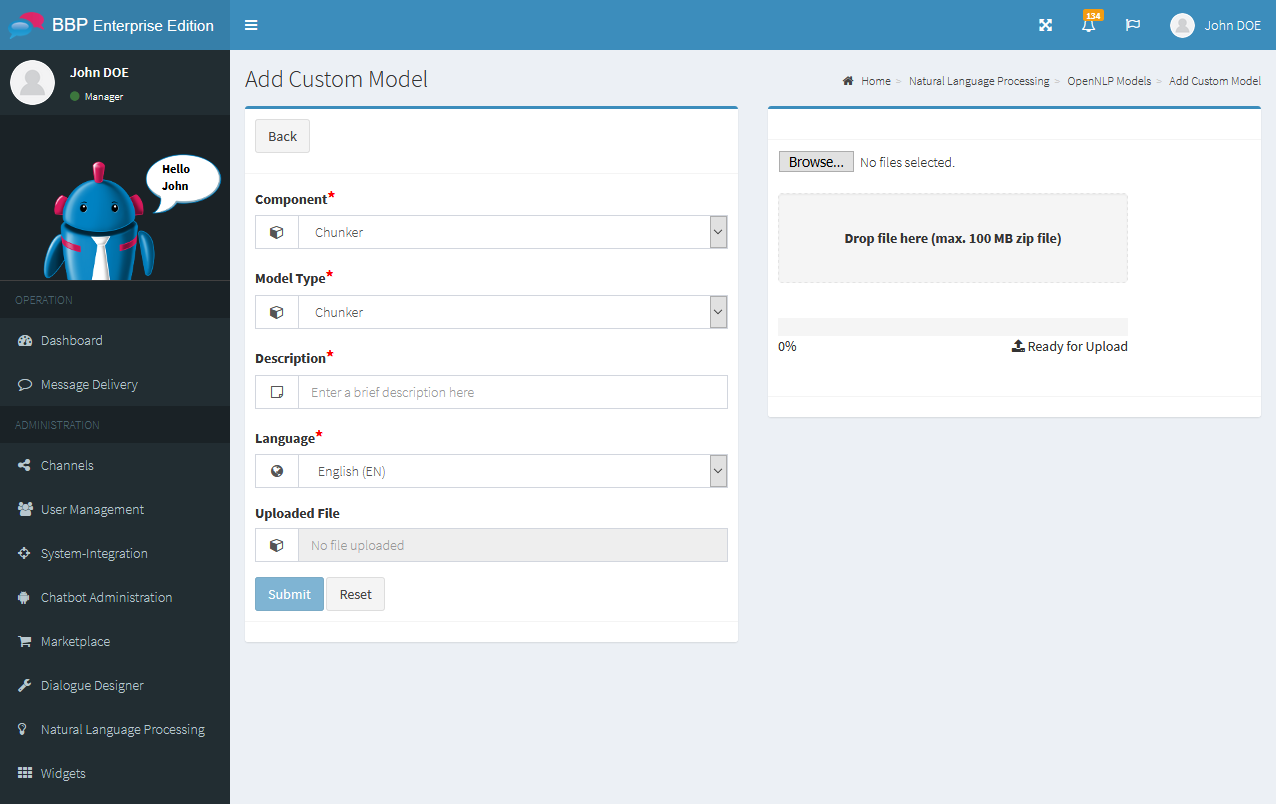
Add custom trained model¶
The pre-trained models might not be available for a desired language, can not detect important entities or the performance is not good enough outside the news domain. These are the typical reason to do custom training of the own model on a new corpus or on a corpus which is extended by private training data taken from the data which should be analyzed.
To add your own model, proceed as follows:
- In the navigation bar, click on
Natural Language Processing→NLP Models→Add Custom Model - Now select the component, model type and language of the model and enter a short description
- Upload the model file by drag & drop in the right panel and check the output in the panel (the file must not be larger than 100 MB and must have the file type
*.bin). Then click onSubmitto register the model.
Hint
The file size for the NLP model can be configured in the system settings of the platform.
Information about how to create custom NLP models can be found in the Apache OpenNLP Developer Documentation.
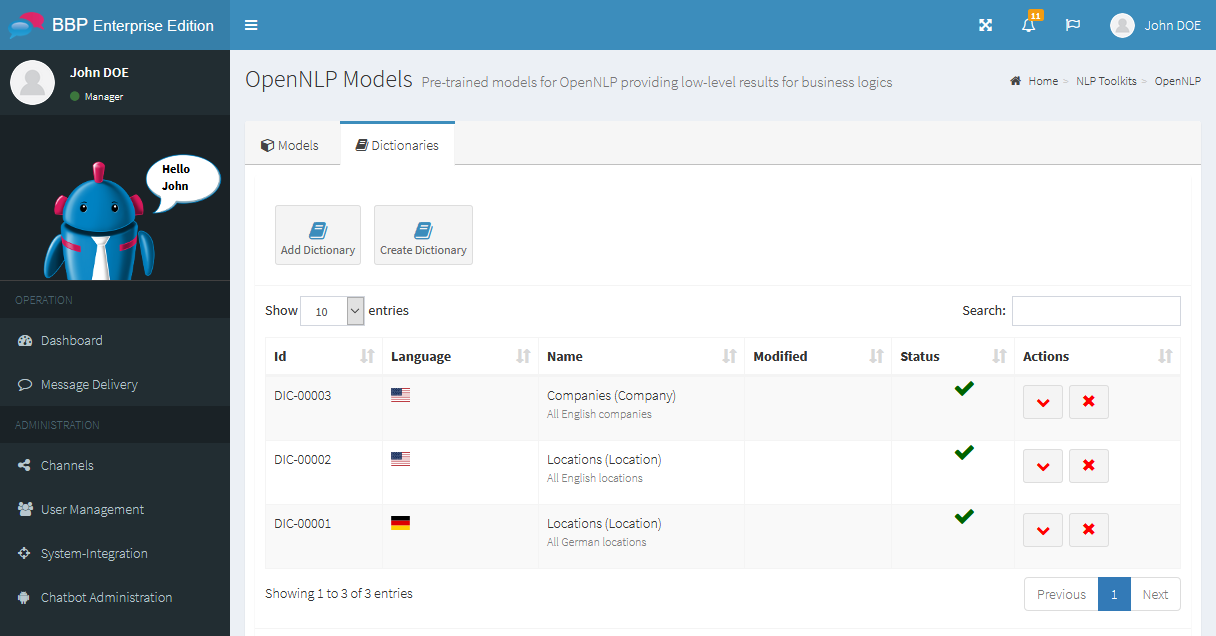
Add prefabricated OpenNLP dictionaries¶
The Business Bot Platform allows you to download pre-built dictionaries so that they can be used by business logics. To add an OpenNLP dictionary to the platform you need an Internet connection. Proceed as follows:
- In the navigation bar, click on
Natural Language Processing→NLP Models→Add Dictionaries - Check the desired NLP dictionary in the box on the top left and then click on
Download - The NLP dictionary is now automatically downloaded and registered to the platform in the background. You can view the download status by clicking the flag icon for background tasks which is in the top navigation bar
Add custom pre-built OpenNLP dictionary¶
The pre-built dictionaries may not be available for a desired language, may not recognize important entities or may not be available for a desired domain. These are the typical reasons for creating custom dictionaries.
To add your own dictionary, proceed as follows:
- In the navigation bar, click on
Natural Language Processing→NLP Models→Add Custom Dictionary - Now select the name, type and language of the dictionary and enter a short description
- Upload the dictionary file by drag & drop in the right panel and check the output in the panel (the file must not be larger than 100 MB and must have the file type
*.dict). Then click onSubmitto register the dictionary.

Hint
The file size for the NLP dictionary can be configured in the system settings of the platform.
Information about how to create custom NLP dictionaries can be found in the Apache OpenNLP Developer Documentation.
Testing the model¶
The best way to gauge reliability is by evaluating the model you have trained. The output of the evaluation will be some scores that indicates the model’s precision and recall metrics as well as the combined F-measure. After training and evaluating the model, you can adjust parameters or the training text itself to work toward improving the evaluation’s metrics.
The NLP - API Tester helps you to send requests to the model and inspect the returned result. The NLP tool is described in the chapter NLP - API Tester.
Use NLP models for business logics¶
All business logics can use the NLP implementation of the Business Bot Platform. The business logic sends a HTTP request to the platform. The web service consumes POST requests with the following values:
| Parameter | Value |
|---|---|
| HTTP Type | POST |
| URL: | https://demo.bbp.local:<port>/bbp/rest/api/1.0/<TenantId>:<ApiId>:<ApiKey>/nlp/opennlp/query/ |
| Parameter | Description | Example Value |
|---|---|---|
<port> |
Platform port | 450 |
<TenantId> |
Tenant identifier | demo |
<ApiId> |
API identifier | u-98edf8d |
<ApiKey> |
API key | 5407807 |
| Body Parameter | Parameter Name | Description | Example Value |
|---|---|---|---|
| Key Parameter 1 | messageText |
Message text | <text>, z.B. Hallo Chatbot |
| Key Parameter 2 | language |
Language of the message (if the parameter is not specified, the language detection model is used to try to detect the language. If the language detector model is not installed, English is used as the default language). | <languageCode> e.g. en or de |
The answer is in JSON notation. A detailed description of the JSON response can be found in the chapter NLP - API Tester.