NLP - API Tester¶
Introduction¶
The NLP-API Tester makes it easy to send HTTP requests to the NLP models and evaluate the response. HTTP requests can be made dynamic by inserting variables. Security and authentication are fully supported. You can visualize, embellish and inspect HTTP responses.
Requirements¶
You must download the NLP model to test it. If no model is installed you will get the following message:
1 2 3 4 5 | { "code": 471, "description": "No Sentence-Detector model loaded for language [en]", "status": "false" } |
You need the following models per language as minimum configuration to get a full NLP response:
- Sentence Detector model
- Tokenizer model
- POS-Tagger model
Send API request¶
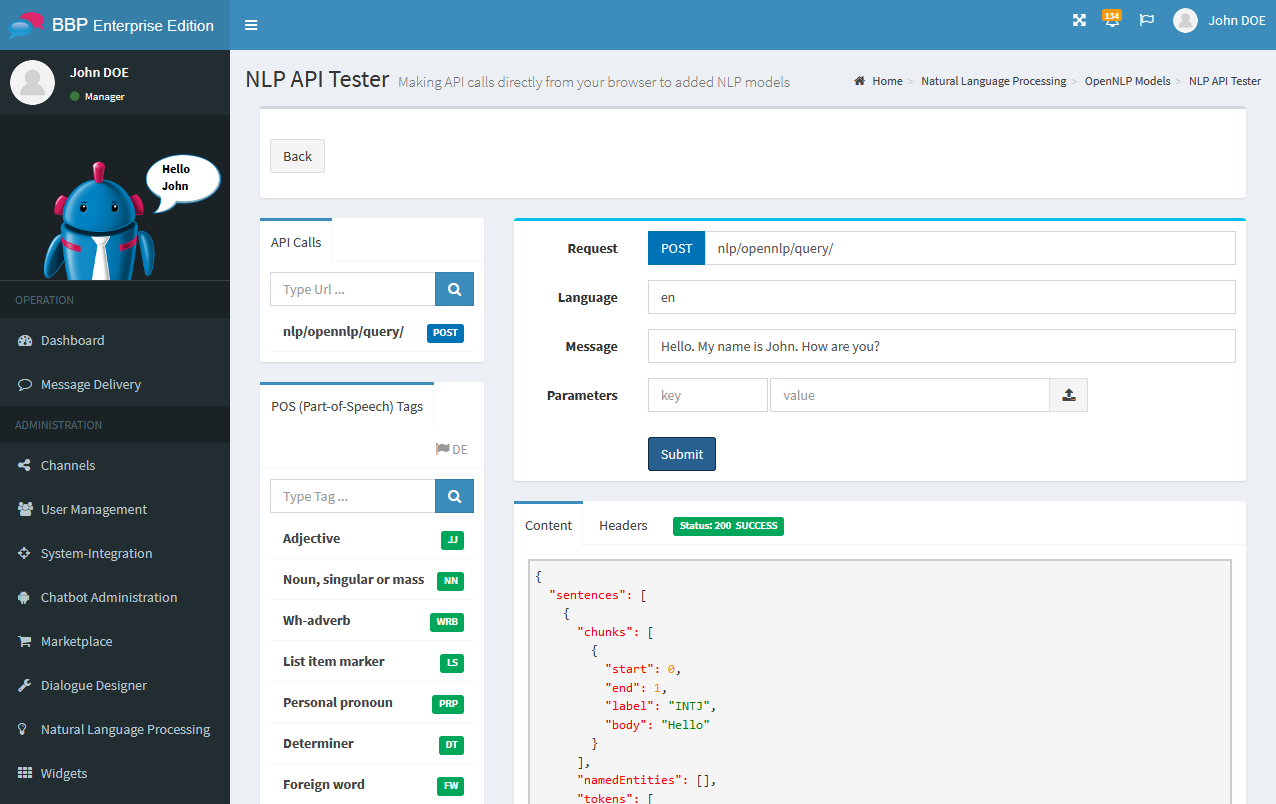
Proceed as follows to send a request to the NLP Web Service:
- Click on
Natural Language Processing→NLP Models→NLP API Testerin the navigation bar - Select the POST method
nlp/opennlp/query/from the componentAPI Calls. Now select the language of the message and specify a message. - Click on
Send. If the reply from the Web Service is successful, the statusStatus: 200 SUCCESSis displayed. In the panelContentyou can now inspect the reply content. In the tabHeadersyou will find the header information of the HTTP response.
Hint
If the parameter language is not specified, the language detector model is used to try to detect the language. If the language detector model is not installed, English is used as default language.
Explanation of the API response¶
The HTTP response of the NLP web service is notated in JSON format. The JSON response depends on the installed NLP models. For example, if no NameFinder model is installed and loaded, then the field for namedEntities will be empty. This is also the case when no result has been found.
Response content (Example data):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 | { "sentences": [ { "chunks": [ { "start": 0, "end": 1, "label": "INTJ", "body": "Hello" } ], "namedEntities": [], "tokens": [ { "probability": 0, "tag": ".", "body": "." }, { "probability": 0, "tag": "UH", "body": "Hello" } ], "parses": "[(TOP (. Hello.))]", "body": "Hello." }, { "chunks": [ { "start": 0, "end": 2, "label": "NP", "body": "My name" }, { "start": 2, "end": 3, "label": "VP", "body": "is" }, { "start": 3, "end": 4, "label": "NP", "body": "John" } ], "namedEntities": [ { "start": 3, "end": 4, "label": "person", "body": "John" } ], "tokens": [ { "probability": 0, "tag": "VBZ", "body": "is" }, { "probability": 0, "tag": "NNP", "body": "John" }, { "probability": 0, "tag": ".", "body": "." }, { "probability": 0, "tag": "PRP$", "body": "My" }, { "probability": 0, "tag": "NN", "body": "name" } ], "parses": "[(TOP (S (NP (PRP$ My) (NN name)) (VP (VBZ is) (NP (NNP John.)))))]", "body": "My name is John." }, { "chunks": [ { "start": 0, "end": 1, "label": "ADVP", "body": "How" }, { "start": 2, "end": 3, "label": "NP", "body": "you" } ], "namedEntities": [], "tokens": [ { "probability": 0, "tag": ".", "body": "?" }, { "probability": 0, "tag": "WRB", "body": "How" }, { "probability": 0, "tag": "VBP", "body": "are" }, { "probability": 0, "tag": "PRP", "body": "you" } ], "parses": "[(TOP (SBAR (WHADVP (WRB How)) (S (VP (VBP are))) (. you?)))]", "body": "How are you?" } ], "predictedLanguage": "en" } |
The example JSON response contains the following sections:
- Predicted language (e.g.
enfor English ordefor German) - Chunker information
- Token information
- Parser information
- Named entities (e.g.
Johnasperson)
Troubleshooting¶
NLP-Tester shows no results¶
Check the browser console to see if the following error is logged:
Cross-Origin Request Blocked: The Same Origin Policy disallows reading the remote resource at https://demo.bbp.local/bbp/rest/api/1.0/..../nlp/opennlp/query/. (Reason: CORS request did not succeed).
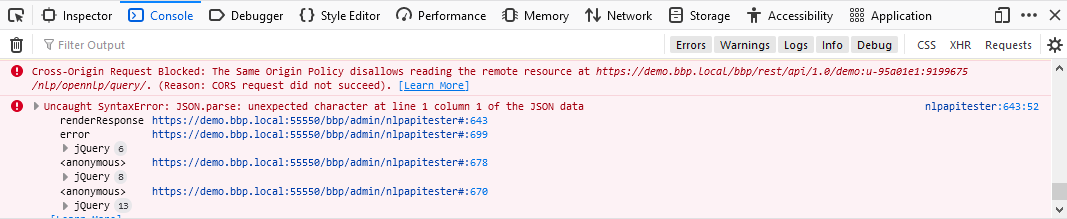
Cross-Origin Resource Sharing (CORS) is a mechanism that uses additional HTTP headers to tell a browser that a web application (BBP) running on an origin (domain) has permission to access selected resources from a server with a different origin. By default only the same point of origin is allowed (security feature).
You can correct the error by checking/adjusting the following parameters of the configuration file bbp.properties to the server port. The server port (for Windows and Linux is set to 55550 by default).
1 | System.Webservices.WebAddress
|
You should also check the ports in the following parameters:
1 2 3 | System.Widget.SSLPort System.Websocket.SSLPort System.InstantMessenger.FileStore.WebAddress |
Reference: POS - English¶
| POS / Tag | Description |
|---|---|
| CC | Coordinating conjunction |
| CD | Cardinal number |
| DT | Determiner |
| EX | Existential there |
| FW | Foreign word |
| IN | Preposition or subordinating conjunction |
| JJ | Adjective |
| JJR | “Adjective, comparative” |
| JJS | “Adjective, superlative” |
| LS | List item marker |
| MD | Modal |
| NN | “Noun, singular or mass” |
| NNS | “Noun, plural” |
| NNP | “Proper noun, singular” |
| NNPS | “Proper noun, plural” |
| PDT | Predeterminer |
| POS | Possessive ending |
| PRP | Personal pronoun |
| PRP$ | Possessive pronoun |
| RB | Adverb |
| RBR | “Adverb, comparative” |
| RBS | “Adverb, superlative” |
| RP | Particle |
| SYM | Symbol |
| TO | to |
| UH | Interjection |
| VB | “Verb, base form” |
| VBD | “Verb, past tense” |
| VBG | “Verb, gerund or present participle” |
| VBN | “Verb, past participle” |
| VBP | “Verb, non-3rd person singular present” |
| VBZ | “Verb, 3rd person singular present” |
| WDT | Wh-determiner |
| WP | Wh-pronoun |
| WP$ | Possessive wh-pronoun |
| WRB | Wh-adverb |
Reference: POS - Description¶
| POS / TAG | Beschreibung |
|---|---|
| ADJA | attributives Adjektiv |
| ADJD | adverbiales oder prädikatives Adjektiv |
| ADV | Adverb |
| APPR | Präposition; Zirkumposition links |
| APPRART | Präposition mit Artikel |
| APPO | Postposition |
| APZR | Zirkumposition rechts |
| ART | bestimmter oder unbestimmter Artikel |
| CARD | Kardinalzahl |
| FM | Fremdsprachliches Material |
| ITJ | Interjektion |
| KOUI | unterordnende Konjunktion mit ``zu’‘ und Infinitiv |
| KOUS | unterordnende Konjunktion mit Satz |
| KON | nebenordnende Konjunktion |
| KOKOM | Vergleichskonjunktion |
| NN | normales Nomen |
| NE | Eigennamen |
| PDS | substituierendes Demonstrativpronomen |
| PDAT | attribuierendes Demonstrativpronomen |
| PIS | substituierendes Indefinitpronomen |
| PIAT | attribuierendes Indefinitpronomen ohne Determiner |
| PIDAT | attribuierendes Indefinitpronomen mit Determiner |
| PPER | irreflexives Personalpronomen |
| PPOSS | substituierendes Possessivpronomen |
| PPOSAT | attribuierendes Possessivpronomen |
| PRELS | substituierendes Relativpronomen |
| PRELAT | attribuierendes Relativpronomen |
| PRF | reflexives Personalpronomen |
| PWS | substituierendes Interrogativpronomen |
| PWAT | attribuierendes Interrogativpronomen |
| PWAV | adverbiales Interrogativ- oder Relativpronomen |
| PAV | Pronominaladverb |
| PTKZU | ``zu’‘ vor Infinitiv |
| PTKNEG | Negationspartikel |
| PTKVZ | abgetrennter Verbzusatz |
| PTKANT | Antwortpartikel |
| PTKA | Partikel bei Adjektiv oder Adverb |
| TRUNC | Kompositions-Erstglied |
| VVFIN | “finites Verb, voll” |
| VVIMP | “Imperativ, voll” |
| VVINF | “Infinitiv, voll” |
| VVIZU | “Infinitiv mit ``zu’‘, voll” |
| VVPP | “Partizip Perfekt, voll” |
| VAFIN | “finites Verb, aux” |
| VAIMP | “Imperativ, aux” |
| VAINF | “Infinitiv, aux” |
| VAPP | “Partizip Perfekt, aux” |
| VMFIN | “finites Verb, modal” |
| VMINF | “Infinitiv, modal” |
| VMPP | “Partizip Perfekt, modal” |
| XY | “Nichtwort, Sonderzeichen enthaltend” |
| ”$ | “,Komma |
| $. | Satzbeendende Interpunktion |
| $( | sonstige Satzzeichen; satzintern |
Reference: Predictable languages (Codes)¶
af/ afr (Afrikaans)ar/ ara (Arabic)ast/ ast (Asturian)az/ aze (Azerbaijani)ba/ bak (Bashkir)be/ bel (Belarusian)bn/ ben (Bengali)bs/ bos (Bosnian)br/ bre (Breton)br/ bul (Bulgarian)ca/ cat (Catalan)ceb/ ceb (Cebuano)cs/ ces (Czech)ce/ che (Chechen)cmn/ cmn (Mandarin Chinese)cy/ cym (Welsh)dk/ dan (Danish)de/ deu (German)et/ ekk (Standard Estonian)el/ ell (Greek, Modern)en/ eng (English)eo/ epo (Esperanto)et/ est (Estonian)eu/ eus (Basque)fo/ fao (Faroese)fa/ fas (Persian)fi/ fin (Finnish)fr/ fra (French)fy/ fry (Western Frisian)ga/ gle (Irish)gl/ glg (Galician)ch/ gsw (Swiss German)gu/ guj (Gujarati)he/ heb (Hebrew)hi/ hin (Hindi)hr/ hrv (Croatian)hu/ hun (Hungarian)hy/ hye (Armenian)id/ ind (Indonesian)is/ isl (Icelandic)it/ ita (Italian)jv/ jav (Javanese)jp/ jpn (Japanese)ca/ kan (Kannada)ka/ kat (Georgian)kk/ kaz (Kazakh)ky/ kir (Kirghiz)ko/ kor (Korean)la/ lat (Latin)lv/ lav (Latvian)li/ lim (Limburgan)lt/ lit (Lithuanian)lb/ ltz (Luxembourgish)lv/ lvs (Standard Latvian)ml/ mal (Malayalam)mr/ mar (Marathi)min/ min (Minangkabau)mk/ mkd (Macedonian)mt/ mlt (Maltese)mn/ mon (Mongolian)mi/ mri (Maori)ms/ msa (Malay)nan/ nan (Min Nan Chinese)de/ nds (Low German)ne/ nep (Nepali)nl/ nld (Dutch)nn/ nno (Norwegian Nynorsk)nb/ nob (Norwegian bokmål)oc/ oci (Occitan)pa/ pan (Panjabi)fa/ pes (Iranian Persian)mg/ plt (Plateau Malagasy)pa/ pnb (Western Panjabi)pl/ pol (Polish)pt/ por (Portuguese)ps/ pus (Pushto)ro/ ron (Romanian)ru/ rus (Russian)sa/ san (Sanskrit)si/ sin (Sinhala)sk/ slk (Slovak)sl/ slv (Slovenian)so/ som (Somali)es/ spa (Spanish)sq/ sqi (Albanian)sr/ srp (Serbian)su/ sun (Sundanese)sw/ swa (Swahili)sv/ swe (Swedish)ta/ tam (Tamil)tt/ tat (Tatar)te/ tel (Telugu)tg/ tgk (Tajik)tl/ tgl (Tagalog)th/ tha (Thai)tr/ tur (Turkish)uk/ ukr (Ukrainian)ur/ urd (Urdu)uz/ uzb (Uzbek)vi/ vie (Vietnamese)vo/ vol (Volapük)war/ war (Waray)zu/ zul (Zulu)